In this case the beginner is me.
This post is going to be different from my usual posts where i’ve worked out the answers in advance. This time i’m going to be working things out as I go along, so when I get things wrong please tell me! What i’m doing is going to be focused on Amazon AWS but could be applied to any other cloud service provider.
I’m also assuming that money is no object, which is never the case!
Terms
Horizontal Scaling – This refers to catering for extra load by bringing extra compute instances online, usually with some sort of load balancing to spread the extra load around.
Vertical Scaling – This refers to catering for extra load by adding extra capacity (cpu’s, ram etc) to existing compute instances.
Elasticity – The ability to scale computing resources of any kind up and down with minimal issues.
Design Goals
A project is no good unless you’ve an idea of what you’re aiming for! So this is what i’m after:
Scalable resourcing – I’m after the ability to scale vertically and/or horizontally depending on capacity requirements. This will be limited by the systems required e.g. The JSS webapp can be scaled in either direction but the backend MySQL database currently can only scale vertically. Clustering currently is not an option until non MySQL databases can be used.
Maximum uptime – Having someone else take care of the infrastructure for you and others does make life more reliable, if only because they don’t want to lose customers. However also having your own design to cope with unexpected failures while prudent, is also expensive.
Minimal service maintenance – See before. Having others to look after this stuff for you saves time for other things. Work always expands to fill the space provided.
Security by Design – The goal here is to restrict traffic to what is necessary for the system to function, the preservation of potentially confidential data behind firewall and other restrictions and generally to make an attacker’s life as miserable as possible.
Jamf Pro with all the trimmings – That’s DEP, VPP, APNS and all the fun Apple stuff that’s becoming a requirement of successfully managing the platform. Ties in with the security requirement above.
Cloud File Distribution – Since this is the easiest way of building a worldwide deployment system, capable of reaching devices at work, at home, on Starbucks wifi, business trips etc then we need to be able to deliver software securely outside the corporate network.
Monitoring – Usual server stuff. CPU, Memory, Disk and Network loadings. Warnings if capacity is close to breach. Warnings if service is offline etc.
I’m intending this to be a high level reference implementation, rather than an all out all encompassing design. Merely enough to get going with enough inherent flexibility to scale and secure further if needed later. I’ll be leaving out firewall configurations, this is just to get the concepts correct.
Services to use
Amazon EC2 – Amazon calls this “resizable compute capacity in the cloud”. What this means is you can have a virtual server with varying capacity depending upon load. The more you use, the more you pay etc.
We’ll be using this to host Apache Tomcat, and thus Jamf Pro.
Elastic IP / Load Balancer – Pretty simple. Dedicated static IP address for your AWS setup. An Elastic IP Address however, belongs to the account and not to a virtual machine instance. It exists until it is explicitly removed, and remains associated with the account even while it is associated with no server instance. If you require more than one server (JSS clustered mode) then you can distribute traffic via the Elastic Load Balancing service.
Required for any kind of Jamf Pro server design, where a single entry point for clients to contact JSS is an essential design consideration.
Amazon S3 – Simple Storage Service: Amazon’s handy online storage facility. Can store single files up to a maximum of 5Tb in size but does have some current (as of time of writing) and annoying limitations which we’ll explore those later.
We will be using this for macOS package distribution purposes.
Amazon RDS – Amazon’s scalable database instance. Provides backups, patch management and other common admin tasks. While you can run a MySQL database on the same compute instance as Jamf Pro, this does impact performance under load.
Using RDS will be useful for avoiding running the database on the same server as the Jamf Pro instance. I personally regard separation of tomcat and database as essential for production environments, partly for performance but mostly for security reasons.
Amazon Route53 – A DNS service. Unless you just want to point your clients at an IP address, this will be handy to make things human friendly. Swap things around later at the lookup level rather than repoint all the clients.
Amazon CloudFront – This provides Amazon’s own CDN front end. Globally distributed proxy servers to cache large content and optimise speed of delivery.
Amazon CloudWatch – Amazon’s own monitoring toolset, allows you to perform real-time monitoring of EC2. This also enabled the auto-scaling feature to dynamically add/remove EC2 compute instances.
Amazon VPC – All of the above assumes that your cloud service will be self contained, however you may wish to extend access to your corporate network (in a limited fashion) to the Jamf Pro server securely. That will allow services such as LDAP to be handled in a more secure way, and not passing over the internet as a whole.
Caveat – There are probably better ways of doing this, but this is literally my first attempt doing any conceptual design with AWS. Please bear with me!
Basic Design
This is a first step design to get the basics of JSS design down on paper.
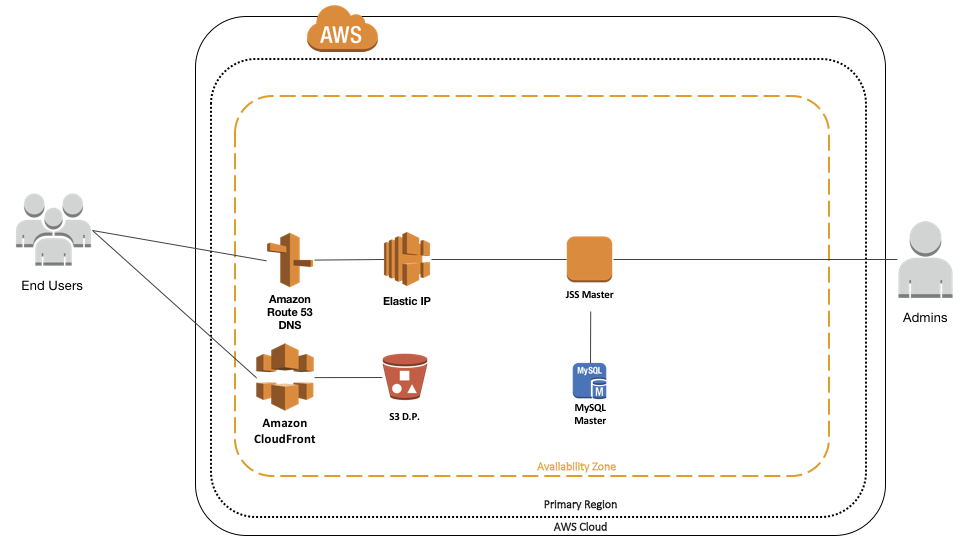
A single DNS service name is suppied via Route 53 so we have a consistent single contact point for end users. This is attached to an Elastic IP so that if anything changes internally to AWS, our DNS record doesn’t need to be updated. This is attached to a single JSS webapp server, which in turn connects to a MySQL RDS server.
For file distribution, we have a single S3 bucket containing all the packages. This is fronted by a CloudFront CDN so we can have regional delivery of packages from a central location, and ideally via HTTPS too.
Intermediate Designs
Now I’m not a fan of single box designs, having been burned so spectacularly by one a few years back. (Not my fault!). So let’s split things up a little.
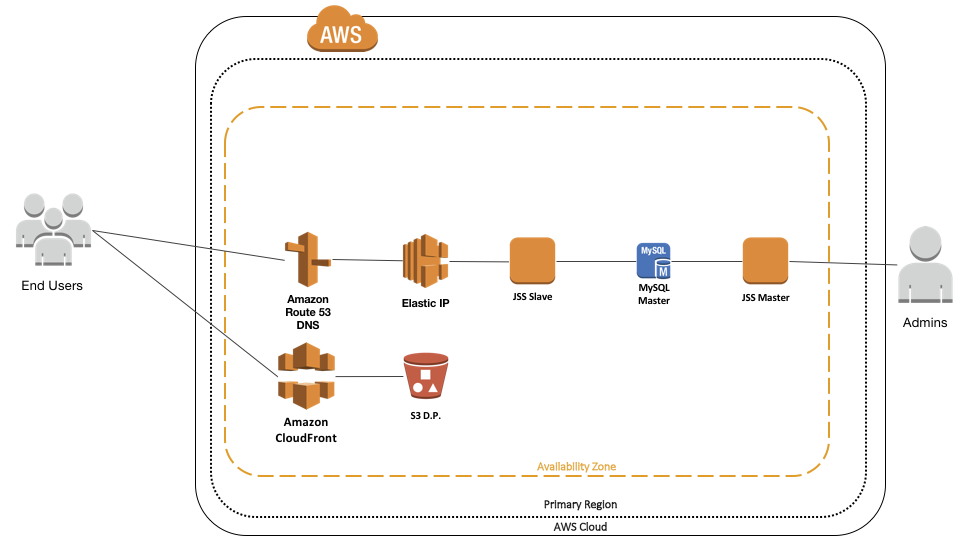
Put the JSS into clustered mode, and create a second server instance. Have the master server off to one side, so the admins can talk to it. The slave server should continue to be public facing and have be placed into “Limited Access Mode”. Not perfect but we have the beginnings of some sort of security now.
However there’s still work to be done.
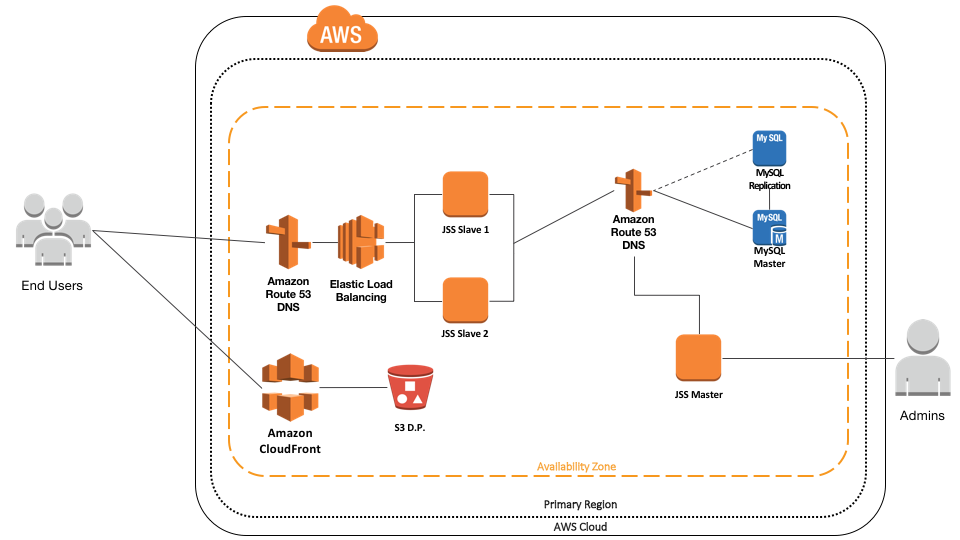
Bit of a change here. Replace the Elastic IP with an Elastic Load Balancer and have two slave JSS instances. Now management traffic will balance between the two restricted slave servers, and we have the beginnings of a system that can be extensible both horizontally and vertically for facing traffic. We can turn our attention to the SQL server.
Now, in my experience trying to cluster JSS on MySQL is a world of pain. Some have got it working with products like Galera Cluster, but that’s not available on AWS. We have to resort to other means to ensure reliability and the simplest but most effective is to set up a second RDS instance and have the primary database periodically replicate to it.
The next thing to do is to put another DNS service name in there, so that if the worst happens and the primary database fails you can swap the DNS record to point to the secondary server and hopefully pick up without too much unrecoverable data loss.
Security
The issue with all of the above is there’s no firewalls, no security, no nothing! Everything is technically on a public facing subnet. Let’s do something about that now.
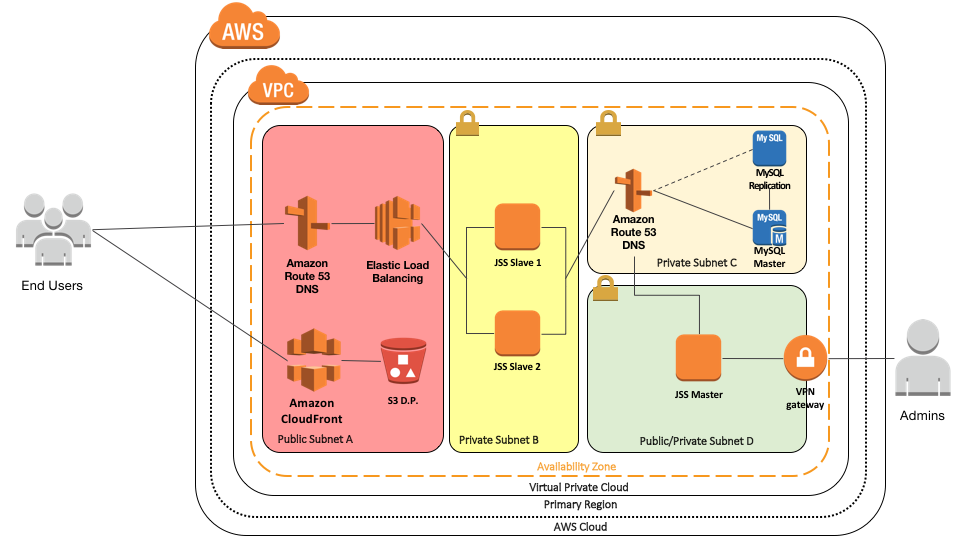
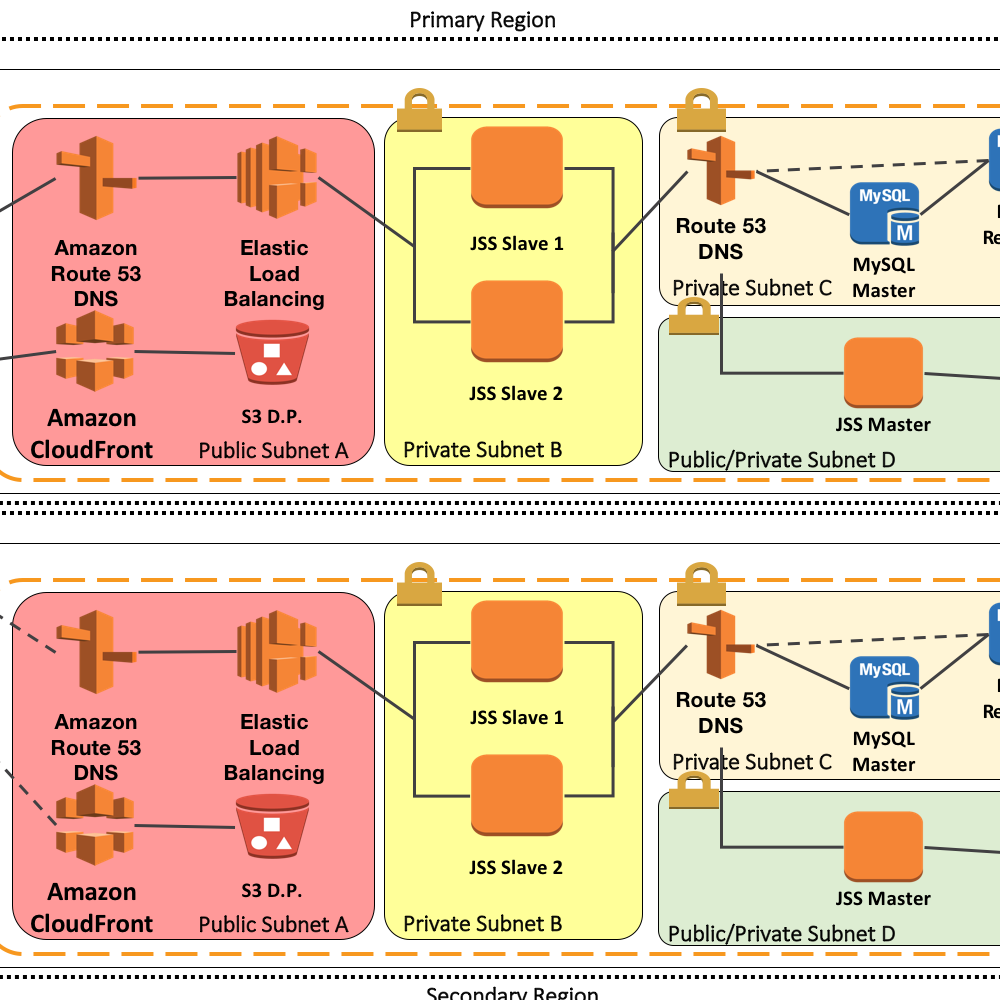
We contain everything in it’s own subnets with access allowed only from specific places. The idea here is traffic from the internet can only get to the load balancer on SSL 443 where we do SSL termination. That traffic is then load balanced to the two slave JSS in their own security subnet. That subnet will only allow specific JSS traffic from the load balancer in.
We now have two more security subnets. We’ll deal with the JSS master first. That has a VPN which allows secure connections from a corporate network in and out. It’s also set up to allow traffic such as APNS out to the wider internet, and MySQL traffic to the database subnet. The database subnet only allows MySQL traffic from the three specific JSS servers to the master server. It also has a failover MySQL server, from which the master periodically replicates itself. A DNS record allows easy switching from one to the other.
By restricting the traffic from specific servers in specific subnets, on specific ports and protocols we can better secure things by segregating access.
AWS Failures?
Looks like plenty of scope for failover, scaling and everything else we set out to achieve. Well there’s one final hurdle that you should consider and it doesn’t happen very often. AWS Region failures.
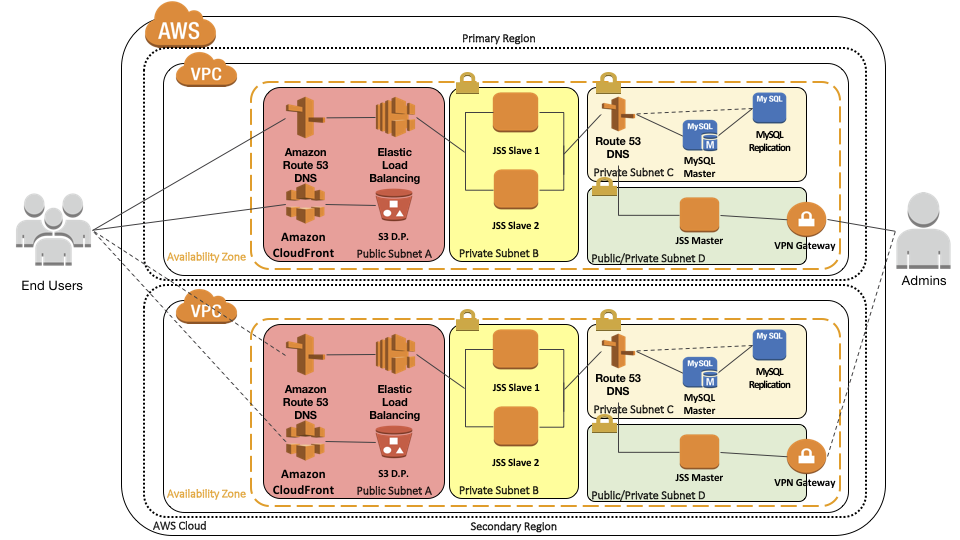
On Tuesday February 28th 2017, Amazon suffered a major S3 outage in their US-East-1 region. That particular datacentre is located in northern Virginia, USA and is very widely used by many, partly due to location but mainly due to pricing. Yes, that’s right Amazon’s cheapest datacentre suffered a failure and everyone there suffered issues.
I was personally affected trying to report spam marketing on the Mac Admins Slack instance and I couldn’t upload screengrabs of the offending messages. Seems Slack is using S3 for file storage in US-East-1. So what can we do about it? Short version, duplicate everything we’ve done into a different Amazon Region. Use DNS to it’s ultmate extent to make failovers to the secondary region as seamless as possible. Add periodic replication of data across AWS to the new region as well. This is the equivalent of setting up a hot swap DR environment in a non cloud environment.
Costing (or can you put a price on reliability?)
So I attempted to use the AWS simple (ha!) calculator and take a look. This calculator is anything but simple. So complicated that I just had to remove the graphic and rewrite this section of the post a day after publishing! The point still remains, how much is data protection and reliability worth to your organisation? I would take the longer term view and suggest that more money up front is preferable to the costs incurred when things go wrong.